Author: Evangelos Bolofis AI Expert at Cognizant Date: June 17, 2025
Introduction: The Bedrock of Breakthroughs
In the world of Generative AI and advanced machine learning, it is easy to become captivated by the complexity of neural architectures and the power of large-scale models. Yet, the most sophisticated AI ever conceived is fundamentally powerless without its lifeblood: data. More importantly, a deep understanding of data’s intrinsic nature is what separates fleeting novelty from true, sustainable innovation.
Every algorithm, every prediction, and every piece of generated content begins with a single, crucial step: understanding the type of data you are working with. This is not merely an academic exercise; it is the bedrock upon which all successful AI systems are built. In this article, we will dissect the fundamental types of data, providing the foundational knowledge you need to architect robust and effective AI solutions.

At the highest level, data is classified into two primary families: Categorical and Numerical. Let’s explore the children of these two great houses.
1. Categorical Data: The Language of Labels
Categorical data describes qualities, characteristics, or groups. Think of it as data that can be placed into distinct buckets or labels. It answers questions like “Which type?” or “What category?” It doesn’t possess mathematical value in itself but is critical for classification and grouping. This family is further divided into two types.
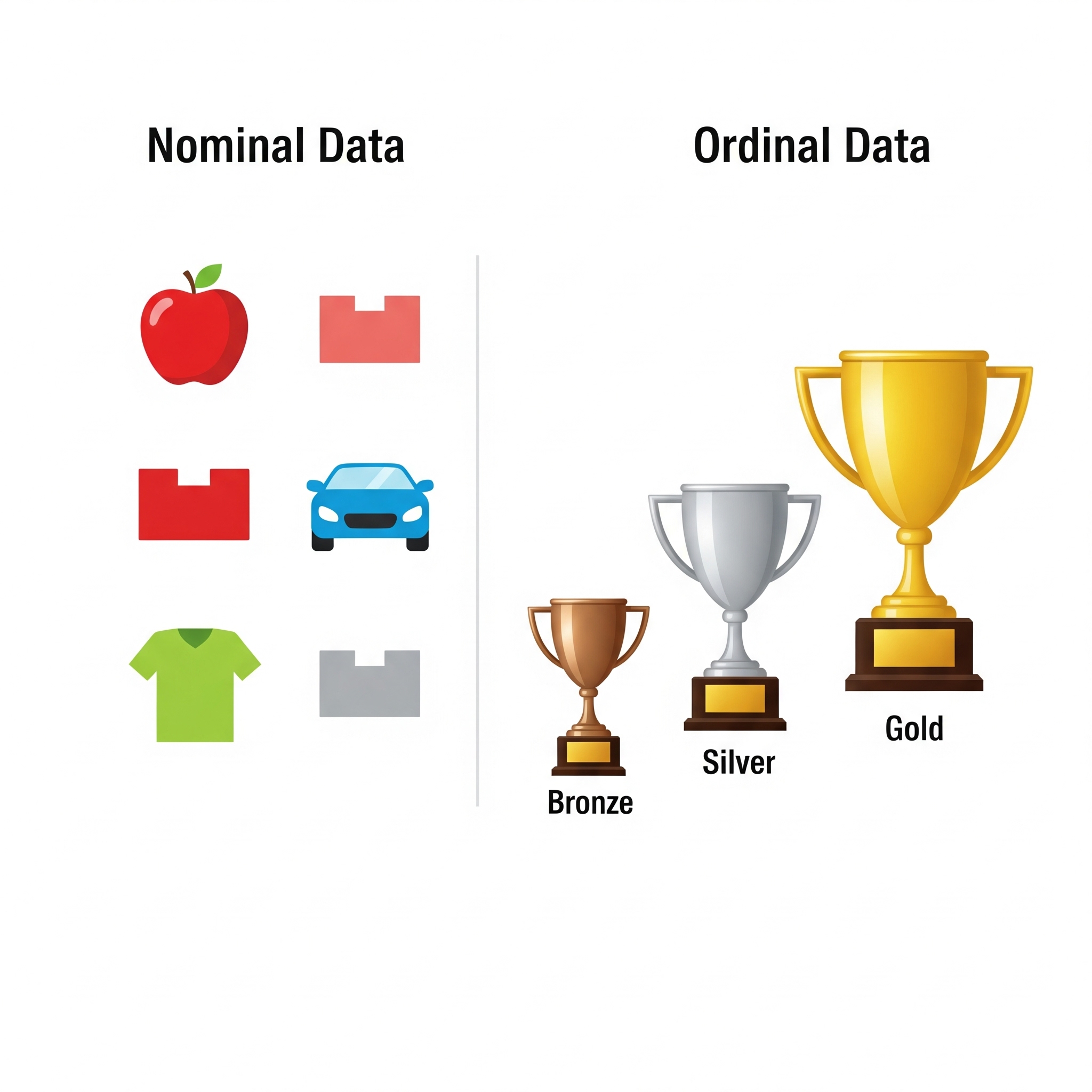
Nominal Data
This is the simplest form of data. It consists of labels or names that have no intrinsic order or ranking between them. Each category is simply distinct from the others.
- Core Concept: Unordered labels.
- Examples:
- Product categories on an e-commerce site (‘Electronics’, ‘Apparel’, ‘Books’).
- Country of origin (‘USA’, ‘Germany’, ‘Japan’).
- The classes in a computer vision task (‘Dog’, ‘Cat’, ‘Bird’).
- Relevance in AI: Nominal data is the cornerstone of classification tasks. When you train a model to identify different objects in an image or classify a customer email as ‘Spam’ or ‘Not Spam’, you are working with nominal data.
Ordinal Data
Ordinal data also consists of labels, but unlike nominal data, these labels have a clear, meaningful order or rank. However, the exact difference between these ranks is not defined or consistent.
- Core Concept: Ordered labels with non-uniform spacing.
- Examples:
- Customer feedback (‘Poor’, ‘Average’, ‘Good’, ‘Excellent’).
- Education level (‘High School Diploma’, ‘Bachelor’s Degree’, ‘Master’s Degree’).
- Priority levels (‘Low’, ‘Medium’, ‘High’).
- Relevance in AI: Ordinal data is invaluable for models that need to understand hierarchy and rank. It powers sentiment analysis, predictive models for user ratings, and risk assessment systems.
2. Numerical Data: The Realm of Measurement
Numerical data represents measurable quantities and is expressed in numbers. This is the data that you can perform mathematical operations on. It answers questions like “How much?” or “How many?” Like its categorical sibling, it has two primary forms.
Discrete Data
This type of data can only take on specific, distinct values. It is almost always an integer because it represents things that can be counted in whole numbers. You cannot have half of a discrete unit.
- Core Concept: Countable whole numbers.
- Examples:
- The number of users who clicked an ad (you can’t have 1.5 clicks).
- The quantity of items in a warehouse.
- The number of processors in a server.
- Relevance in AI: Discrete data is central to forecasting and count-based predictions. Models predicting inventory needs, website traffic, or the number of defects in a manufacturing batch all rely on discrete data.
Continuous Data
Continuous data can take any numerical value within a given range. It can be broken down into finer and finer decimal units. It represents things that are measured, not counted.
- Core Concept: Measurable values within a range.
- Examples:
- The temperature of a data center (e.g., 21.75°C).
- The price of a stock.
- The time it takes for a model to run a query (e.g., 0.052 seconds).
- Relevance in AI: Continuous data is the foundation of regression tasks—one of the core pillars of machine learning. Predicting house prices, forecasting financial markets, or optimizing the power consumption of a system are all problems that operate on continuous data.

Conclusion: From Foundation to a Future of Innovation
Why does this fundamental taxonomy matter to a GenAI innovator? Because the type of data you hold dictates your entire strategy.
- It determines the model architecture you can use.
- It influences the pre-processing techniques required to prepare your data.
- In Generative AI, it defines how you can create realistic synthetic data—generating plausible ordinal reviews is a vastly different challenge from generating continuous financial time-series data.
Understanding whether your data is nominal, ordinal, discrete, or continuous is the first and most critical step in the journey from raw information to transformative artificial intelligence. It is the language our models speak, and fluency is non-negotiable.
At ebolofis.ai, we believe that mastery of the fundamentals is what enables the creation of revolutionary technology. Stay tuned for our next post, where we will explore how to pre-process these data types for optimal model performance.
