Beyond the Buzzwords: Why Statistical Thinking is Your Most Powerful Data Science Tool
“You’ve got people who don’t answer the question. They’ve just done analysis and they don’t know why and they don’t know the statistics well enough underneath it to know what they’re actually doing.”
– Anna Kwiatkowska, Deputy Director of Data Science at HMRC (2023)
This quote cuts to the heart of a critical challenge in the world of data science. In a field defined by powerful algorithms and massive datasets, it’s surprisingly easy to fall into the trap of doing analysis for analysis’s sake. The result is a mountain of work that produces zero tangible value, drains resources, and ultimately erodes trust in data-driven initiatives.
The antidote isn’t a more complex model or a bigger dataset. It’s a more fundamental skill: statistical thinking. This isn’t just about knowing your formulas; it’s a business philosophy that provides the critical framework to turn raw data into actionable wisdom.
This post will explore how you can use statistical thinking as your primary tool for critical analysis, ensuring every project you undertake is built for impact.
The High Cost of Mindless Analysis
When data scientists work without a clear “why,” they risk committing statistical fallacies. A statistical fallacy is the act of drawing incorrect, and often costly, conclusions from data due to a misunderstanding of the business problem, the data itself, or the results of the analysis.
Failing to apply critical, statistical thinking can lead you down incorrect avenues for weeks, only to realize your entire premise was flawed. It’s how companies misinterpret a correlation for causation and launch expensive marketing campaigns that are doomed to fail. True success in data science isn’t measured by the complexity of your analysis, but by the value of the decisions it enables.
Climbing the Wisdom Pyramid: Your Roadmap from Data to Decision
To ensure we are creating value, we can use the classical ‘Data, Information, Knowledge, Wisdom’ (DIKW) model as our guide. It illustrates the journey from raw inputs to high-level insight, with each step building on the last.
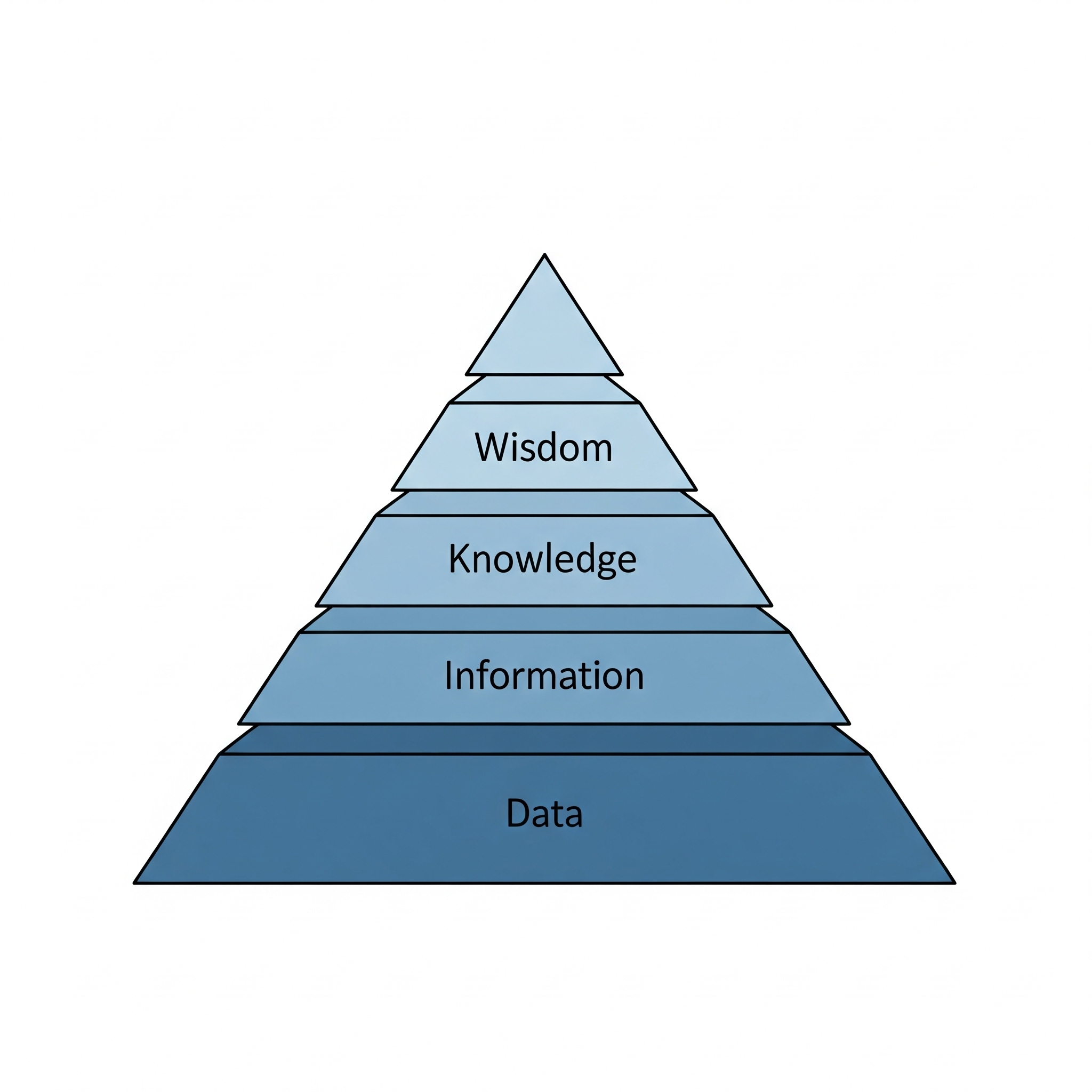
- Data and its types: This is the foundation—raw, unorganized facts, figures, and signals. Think of raw server logs, customer transaction records, or sensor readings. By itself, it has no context and offers no insight.

- Information: This is data that has been organized and structured. By asking questions like “who, what, when, where,” we add context. For example, organizing sales data by region and time period turns raw numbers into useful information about sales performance.
- Knowledge: This is the synthesis of information to answer “how” questions. By analyzing the contextualized information, we uncover patterns and relationships. This is where we might discover that a certain customer demographic responds strongly to a specific type of promotion.
- Wisdom: This is the pinnacle of the pyramid. It moves beyond patterns to answer the “why” questions and involves applying judgment and experience to the knowledge we’ve gained. Wisdom isn’t just knowing that a promotion works; it’s understanding why it works and having the judgment to decide if, when, and how to deploy it to achieve a specific business objective effectively and ethically.
Applying Wisdom to the Modern Challenge of Big Data
The DIKW framework is more relevant than ever in the age of “Big Data.” Big Data isn’t just about size; it’s defined by a set of characteristics known as the Five Vs, each presenting a unique challenge that requires wisdom to navigate.
- Volume: The immense amount of data being collected.
- Velocity: The incredible speed at which data is created and flows into our systems from sources like social media and networks.
- Variety: The diverse nature of data, which can be structured (like in a database), semi-structured, or completely unstructured (like text from emails or videos).
- Veracity: The accuracy and quality of the data. This addresses critical issues like missing data or biases that can poison any analysis.
- Value: The ultimate potential of the data to provide insights.
While technology can help us handle the Volume, Velocity, and Variety, it is human wisdom and sound statistical thinking that allow us to ensure Veracity and extract real Value. Without them, the other three Vs are just noise.
The Golden Rule: Problem First, Technique Second
This brings us to the most important, actionable principle: the starting point of any data science project must be to clearly define the business problem.
Only after you have a well-defined problem statement can you select the most appropriate technique to solve it. One of the biggest challenges data scientists face is the pressure to use complex or cutting-edge methods when they aren’t necessary. At times, a straightforward statistical analysis will provide most, if not all, of the answers, negating the need for complex and time-consuming machine learning activity.
The goal is not to show off a technique; it is to achieve the required business outcome. By letting the problem dictate the method, you ensure your work remains relevant, efficient, and valuable.
What steps does your team take to ensure you’re solving the right business problem before diving into analysis? Share your thoughts in the comments below.
